Migrating a Google Sheet to a directory of Markdown files with Nu Shell
As a part of building this site I had to migrate over all of my personal library's data from this Google Sheet. This website's content is powered by folders of Markdown files with YAML frontmatter data, so I wasn't quite sure how I could translate rows from my CSV into individual files within my /private/books folder in my notebook.
But then I remembered this excellent video by JT, the creator of Nu Shell, where they used Nu Shell's powerful table-based pipelines to prune unused dependencies from the Nu Shell repository itself. Nu Shell has these excellent to and from commands that are just so elegant, and I remembered that they supported CSV and YAML!
First I exported my Sheet to a CSV using the option in the Google Sheets file menu. Then I opened my terminal and typed nu to enter Nu Shell.
Thinking in pipelines was tricky for me, and the thing that I banged my head against for a while was how to perform an operation over each row in the table. The command turned out to be right under my nose (and listed on the Working with lists docs page), but I was looking at the Working with tables links and missed it for a while. The syntax of these little lambdas inside of each are neat, and unsurprisingly remind me a lot of Rust.
I've split up my commands across multiple lines here following this documentation, but I typed them directly into the command line which was a little gnarly to debug. I still need to learn how to write Nu Shell scripts (and get better with shell scripts in general tbh).
# Command for all books with cover images
(
open ./library.csv |
where coverImg != "" |
each { |book|
$book |
to yaml |
save $"($book.coverImg | str substring $"0,(
$book.coverImg |
str index-of "."
)" ).md"
}
)
# Command for all books without cover images
(
open ./library.csv |
where coverImg == "" |
each { |book|
$book |
to yaml |
save $"($book.title).md"
}
)I have two separate commands above because some of my books have cover images (and therefore are possibly ready to be published to my library) and some do not. Since the name of the cover image file was the closest thing I had to a slug I decided to just chop off the file extension using the str substring command. This command took me a while to find too, I was stuck looking for a string version of slice and those only seem to be for data frames.
This got me the following YAML in a .md file for each book. Note there are no end characters on this YAML, the --- that should mark the start of the Markdown body:
---
show: "TRUE"
title: Alone Together
subtitle: Why We Expect More From Technology and Less From Each Other
author: Sherry Turkle
coverImg: alone-together.jpg
publisher: Basic Books
publishLocation: "New York, NY"
editor: ""
publishDate: 2011
firstPublished: 2011
edition: ""
category: Nonfiction
language: en
translator: ""
coverType: Paperback
pages: 360
format: Printed Book
locId: HM851.T86 2010
isbn: 978-0-465-02234-2
issn: ""
tags: "technology, culture"
isBorrowed: "FALSE"
borrowedBy: ""
rating: 3
status: Unread
review: "Started but never finished. I bet there's good stuff at the end."
Then I did a series of find and replace operations using the RegEx tool in VS Code by hitting Cmd + Shift + F and then selecting the icon with an asterisk in it (pictured below). The first one was to turn the Review into the body of the post:
- Find
review: "(.+)" - Replace with
---\n\n\n$1
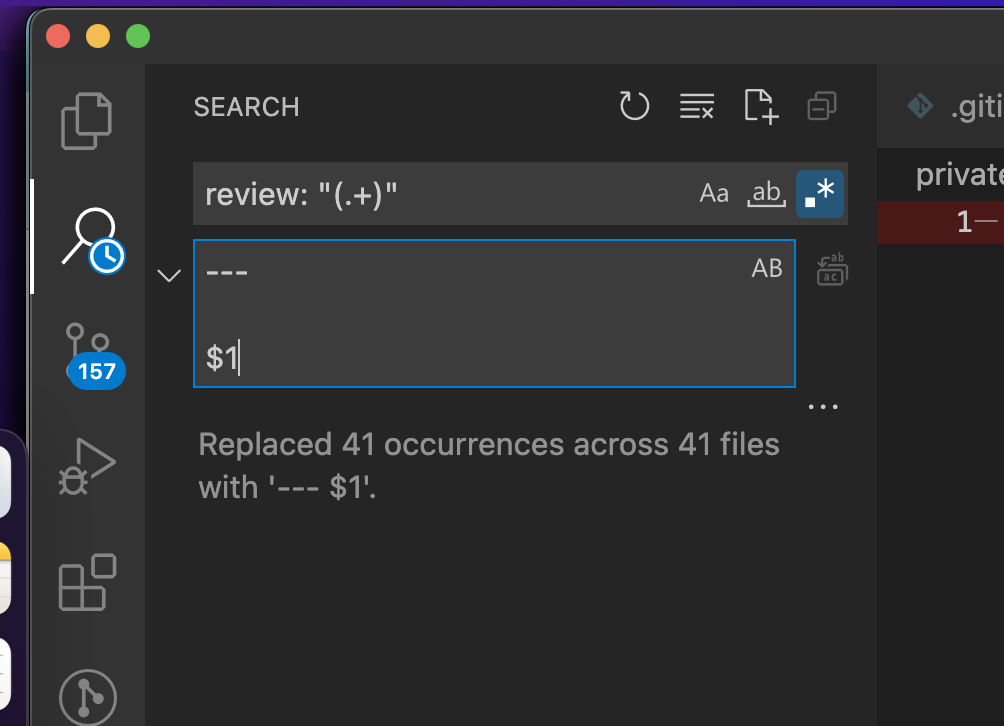
I learned that you can use RegEx capture groups in the VS Code find and replace, super useful! with it I also was able to convert "FALSE" to false, and remove entries with no data, across all my book files at once.
#todo finish process notes